FloodDiff是一個以影像學習為基礎的淹水模型,用於淹水水深估計。它基於I2SB框架,能高效地將DEM 映射為淹水深度預測,並透過Transformer嵌入與Cross-Attention 機制的時間序列降雨編碼,捕捉降雨的時序依賴性以提升預報準確度。同時,FloodDiff結合VQGAN在壓縮潛在空間中進行編碼與解碼,大幅提高運算效率,支援近即時的防災應用。

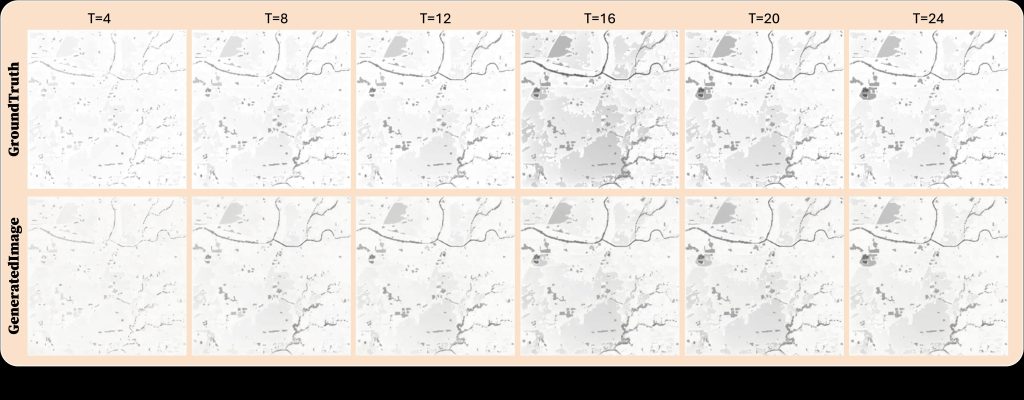
本研究以2024年7月25日卡努颱風的降雨事件作為案例分析。此期間,均方根誤差(RMSE)與分數技巧評分(FSS)均出現顯著波動,凸顯在快速變化的淹水情境下進行精準預測的挑戰。量化結果顯示,RMSE峰值達0.12公尺,為24小時事件中最大水深預測誤差。儘管時間變異明顯,各空間尺度下的FSS值皆穩定高於理論門檻FSSₜ,顯示其具備可靠的空間模擬表現。展示了TUFLOW模型模擬的淹水潛勢圖與FloodDiff模型生成影像的比較。整個模擬過程中,FloodDiff在主要淹水區的預測上保持高度的空間一致性。特別是在T=16至T=20的洪水擴張階段,FloodDiff的預測結果在範圍與空間結構上均與真實值高度吻合。整體而言,結果顯示FloodDiff能有效捕捉淹水範圍的時間演化,並可靠地辨識高風險區域,證實其在複雜降雨條件下模擬動態洪水情境的潛力與穩健性。